任务式训练
提供模型训练的功能,也支持从开发环境直接创建任务式训练;支持单机和多机训练;支持查看训练日志和资源使用率。
创建任务式训练
左侧功能栏选择“训练管理->任务式训练”;
单击右上角“创建任务式训练”;
按照页面提示配置参数:
表 167 创建任务式训练参数 名称
必填项
说明
任务式训练名称
是
他人访问权限
是
具体参见 他人访问权限
任务类型
是
分为“常规任务”、“批量任务”
优先级
是
影响任务排队时的启动顺序
数据
是
参考 数据管理
可以添加多个,并选择是否只读挂载
算法
是
“常规任务”:只能选择一个算法
“批量任务”:需要在展开菜单中为单个任务分别指定算法
可以选择是否只读挂载
保存模型地址
是
只需选择一个模型地址。
批量任务的每个任务输出在
任务式训练名称-任务编号的子目录中。实际训练脚本无需感知,平台会根据 任务式训练目录结构 进行映射。
分布式模式
是
不同的模式“计算节点数量”配置不同
TensorFlow 模式需要额外指定“参数服务器数”
不同的模式的运行指令差异较大
单节点规格
是
单个计算节点的配置
节点名称
否
指定任务式训练可运行的节点,不可与“驱动版本”、“专属资源池”同时指定
4.2 版本新增: 支持指定可运行节点
驱动版本
否
选择 MLU 或 GPU 规格时可用
2.3 版本新增: 支持选择驱动版本。
专属资源池
否
指定任务式训练运行的专属资源池
5.0 版本新增: 支持选择专属资源池。
镜像
是
镜像适用范围需包含“任务式训练”
镜像适用板卡类型需和单节点规格一致
节点数
是
每个任务总的资源量为
单节点规格 x 计算节点数量参数服务器数
否
仅TensorFlow 模式需要,0 表示使用 AllReduce 模式
参数服务器的规格为
1核1G,无法修改运行指令
是
参见下文 运行指令说明
“批量任务”需要在展开菜单中为单个任务分别指定运行命令
断点续训
否
参数详见 断点续训参数
该功能与“故障重启”功能互斥
5.0 版本新增: 支持断点续训
故障重启
否
启用后,可配置最大重启次数
该功能与“断点续训”功能互斥
5.1 版本新增: 支持故障重启
数据准备
否
参见下文 数据准备说明
终端
否
参见下文 调试终端说明
使用时长
是
4.3 版本新增: 支持配置使用时长
模型
否
可以选择多个,仅只读挂载
存储卷
否
可以选择多个,有写入权限
生命周期脚本
否
参考 生命周期脚本
表 168 断点续训参数 名称
必填项
说明
最大续训次数
是
故障后,任务式训练最大重试次数,管理员可配置最大上限
优雅关闭时间
是
任务式训练结束或中断时,在该时间段内运行指令未结束,会强制终止容器, 管理员可配置最大上限
弹性训练
否
详见下文 弹性训练
性能检测
否
详见下文 性能检测
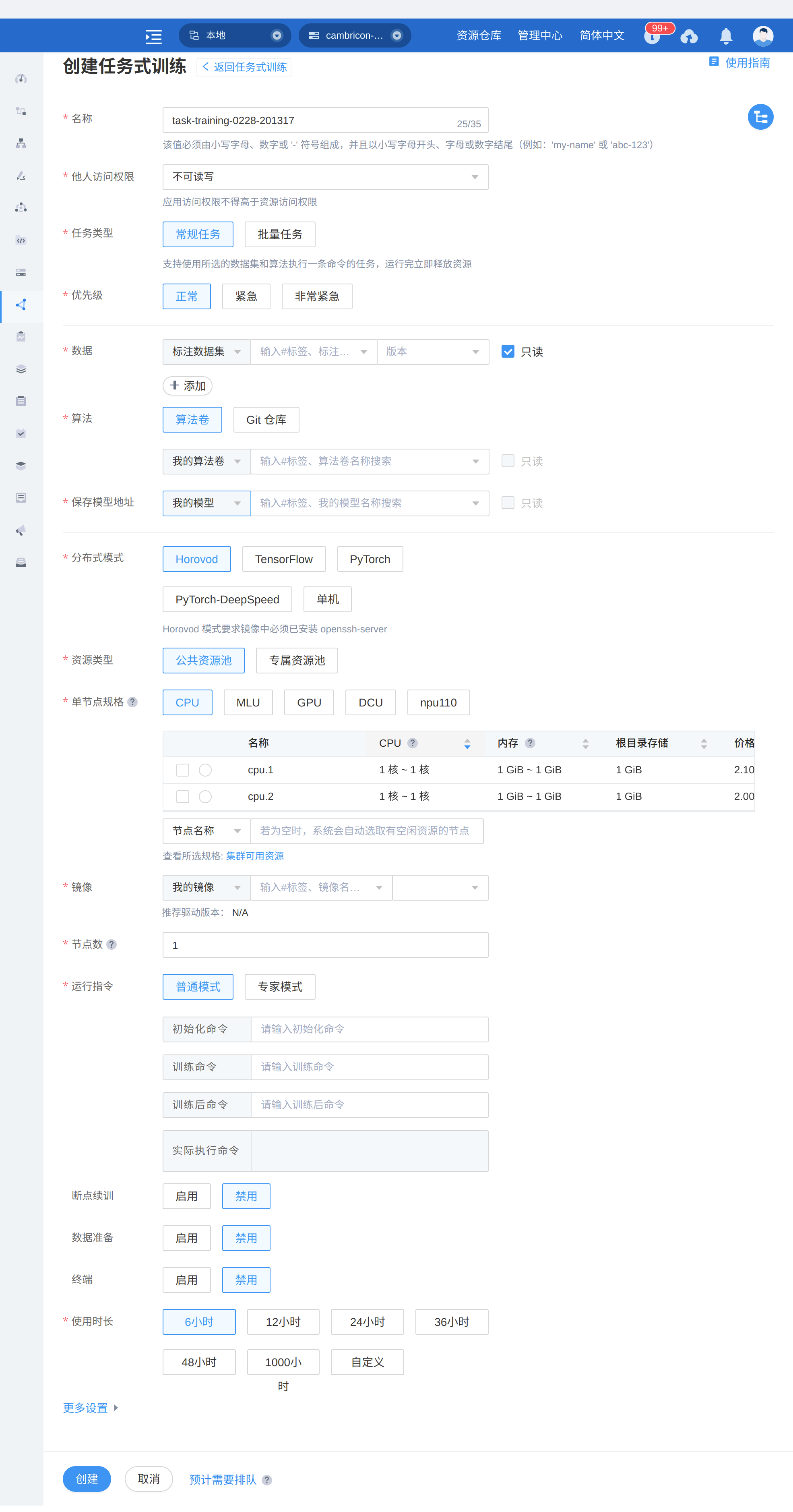
图 234 创建任务式训练
排队预测;
在创建按钮的右边会显示是否需要排队的信息,参考 排队预测 。
单击“创建”。
任务式训练目录结构
单个任务式训练容器内的目录结构为:
/
└── workspace
├── algorithm(创建时选择的算法卷)
├── anno_dataset
│ └── 标注数据集名字 A
│ └── annotation(选择某个版本的标注数据时,该版本的标注文件)
├── dataset
│ ├── private
│ │ ├── 我的数据集名字 A
│ │ └── 我的数据集名字 B
│ └── favorite
| ├── 收藏数据集名字_A |
| │ └── 收藏数据集版本名字_V1 |
| └── 收藏数据集名字_B |
| └── 收藏数据集版本名字_V1 |
├── model
│ ├── pretrained
│ │ ├── 预训练模型名字 A
│ │ └── 预训练模型名字 B
│ ├── private
│ │ ├── 我的模型名字 A
│ │ └── 我的模型名字 B
│ └── favorite
| ├── 收藏模型名字_A |
| │ └── 收藏模型版本名字_V1 |
| └── 收藏模型名字_B |
| └── 收藏模型版本名字_V1 |
├── outputs(创建时选择的保存模型地址)
└── volume
├── 存储卷名字 A
└── 存储卷名字 B
节点规格说明
节点规格是任务式训练中单个节点的资源配置。
3.5 版本新增: 支持使用多个规格创建任务式训练。
支持创建时选择多个规格,此时:
平台会使用每个规格分别创建任务式训练,当其中一个规格的任务成功运行,使用其他的规格的任务会被自动删除。
最终只有一个任务进入运行状态。
选择的多个规格在调度时是等价的,适用于期望尽快用任意一个规格来训练的场景。
预测排队时,只要其中一个规格能立即启动,就会提示该任务能立即启动。
4.0 版本新增: 支持根据所选规格查看集群可用资源
选择一个或多个规格后,单击规格列表下面的 “集群可用资源” 链接;
页面下方会弹出一个表格,展示所选规格对应的可调度节点;
信息包括节点名称,状态,OS 和内核版本,内存, CPU 信息,AI资源信息,驱动版本,适用算力规格和目前使用情况,以表格形式展示;
表格中内存,CPU 核数,AI 资源数量以分数形式展示,意义为(已经使用的资源 / 资源总量);
状态为空闲时,表示规格申请的资源小于等于节点目前可用的资源;状态为紧张时,表示规格申请的某个或某些资源大于节点目前可用的资源;
目前使用情况的条目显示格式为 1(1):application-name:
1: 物理卡,即板卡在节点中的位置;
(1): 虚拟卡,即板卡切分之后的虚拟卡序号;
application-name: 应用名称。
4.5 版本新增: 创建任务式训练按照人工智能板卡型号筛选算力规格
选择非 CPU 类型的算力规格;
在算力规格类型下方会出现具体的人工智能板卡型号;
在板卡型号下方统计了当前所有在排队中的应用所需的各型号板卡数量;
选择一个或多个人工智能板卡型号,算力规格列表会根据所选型号过滤。
运行指令说明
所有模式下,运行指令需要以可执行文件开头,如下的命令是非法的:
KEY=VALUE python3 train.py
因为 KEY=VALUE 不是可执行文件,而是 bash 中设置环境变量的便捷操作。
命令中包含多条语句的,也是非法的,如:
python3 train.py && python3 evaluate.py
此时可以在命令开头加上 bash -c ,如:
bash -c "KEY=VALUE python3 train.py && python3 evaluate.py"
分布式模式说明
Horovod 模式
为简化运行指令,平台:
对于 OpenMPI,设置了环境变量
OMPI_MCA_orte_default_hostfile=/etc/mpi/hostfile。hostfile内包含了节点名称和slots数目,如对于一个2机4卡的训练,hostfile的内容为:server1 slots=4 server2 slots=4
slots为单节点规格中 GPU 或 MLU 的卡数;如果是 CPU 规格,则为1。对于 MPICH,设置了
HYDRA_HOST_FILE=/etc/mpi/mpich_hostfile环境变量,同样是2机4卡的训练,其内容为:server1:4 server2:4
设置了
HYDRA_IFACE=eth0环境变量对不包含
mpirun的运行指令,自动添加前缀(仅适用 OpenMPI):mpirun --allow-run-as-root \ -np ${进程数量} \ -bind-to none -map-by slot \ -x NCCL_DEBUG=INFO -x LD_LIBRARY_PATH -x PATH \ -mca pml ob1 -mca btl ^openib
如有一个 4机4卡 的任务式训练,算法文件为 train.py ,用户可输入运行指令:
python /workspace/algorithm/train.py
平台实际运行指令为:
mpirun \
--allow-run-as-root \
-np 16 \
-bind-to none -map-by slot \
-x NCCL_DEBUG=INFO -x LD_LIBRARY_PATH -x PATH \
-mca pml ob1 -mca btl ^openib \
python /workspace/test/train.py
如果输入的运行指令包含 mpirun ,则需要输入完整的 mpi 参数,
此时平台不会修改用户的输入指令。比如用户可以输入:
mpirun -np 16 \
-bind-to none -map-by slot \
-x NCCL_DEBUG=INFO -x LD_LIBRARY_PATH -x PATH \
-x NCCL_SOCKET_IFNAME=^lo,docker0 \
-mca pml ob1 -mca btl ^openib \
-mca btl_tcp_if_exclude lo,docker0 \
python /workspace/algorithm/train.py
注意不需要指定 -H 或者 -hostfile ,因为平台已经设置了 OMPI_MCA_orte_default_hostfile
和 HYDRA_HOST_FILE 环境变量。
更多 Horovod 分布式训练内容,可以查看官方文档:https://horovod.readthedocs.io/en/stable/ 。
TensorFlow 模式
平台会在任务式训练的每个节点上自动设置 TF_CONFIG 环境变量,
以满足 使用 TensorFlow 进行分布式训练的要求 。对于不同的分布式架构 TF_CONFIG 内容不完全相同,用户首先需要填写 参数服务器数 来确定自己的分布式架构。
对于 PS-Worker 架构的分布式训练,TF_CONFIG 内容如下:
PS 节点
{ "cluster": { "ps": ["${PS_HOST}"], "worker": ["${WORKER_HOST}"] }, "task": { "type": "ps", "index": "${VK_TASK_INDEX}" }, "environment": "cloud" }
Worker 节点
{ "cluster": { "ps": ["${PS_HOST}"], "worker": ["${WORKER_HOST}"] }, "task":{ "type": "worker", "index": "${VK_TASK_INDEX}" }, "environment": "cloud" }
对于 AllReduce 架构的分布式训练, TF_CONFIG 内容如下:
{
"cluster": {
"worker": ["${WORKER_HOST}"]
},
"task": {
"type": "worker",
"index": "${VK_TASK_INDEX}"
},
"environment": "cloud"
}
如果任务式训练运行的 TensorFlow 代码中使用 tf.distribute.Strategy API ,
TensorFlow 会处理 TF_CONFIG ,用户无需感知。
更多 TensorFlow 分布式训练内容,可以查看官方文档:https://tensorflow.google.cn/guide/distributed_training?hl=zh-cn 。
PyTorch 模式
为简化运行指令,平台
设置了
MASTER_PORT、MASTER_ADDR、WORLD_SIZE、RANK和SLOTS环境变量,其中SLOTS为单节点规格中 GPU 或 MLU 的卡数;如果是 CPU 规格,则为1。默认将分布式所需的环境变量,自动添加到运行指令中,用户只需填写单机训练时的命令。如有一个
2机4卡的任务式训练,算法文件为train.py,运行指令为:
python /workspace/algorithm/train.py
平台实际运行指令为:
# master
python \
-m torch.distributed.launch \
--nproc_per_node=4 --nnodes=2 \
--node_rank=0 \
--master_addr=localhost --master_port=2222 \
/workspace/algorithm/train.py
# worker
python \
-m torch.distributed.launch \
--nproc_per_node=4 --nnodes=2 \
--node_rank=1 \
--master_addr=${master address} --master_port=2222 \
/workspace/algorithm/train.py
若用户输入的运行指令中包含 torch.distributed.launch 或者不是以 python 或 python3 开头,则认为用户填写的是分布式训练命令,平台对运行指令不做修改,比如用户输入运行指令:
torchrun \
--nnodes ${WORLD_SIZE} \
--nproc_per_node ${SLOTS} \
--node_rank ${RANK} \
--master_addr ${MASTER_ADDR} \
--master_port ${MASTER_PORT} \
/workspace/algorithm/train.py
平台实际运行指令即为用户输入的指令。
更多 PyTorch 训练内容,可以查看官方文档:https://pytorch.org/docs/stable/index.html 。
PyTorch-DeepSpeed 模式
4.3 版本新增: 支持 PyTorch-DeepSpeed 模式
平台
设置了
MASTER_PORT、MASTER_ADDR、WORLD_SIZE、RANK和SLOTS环境变量,其中SLOTS为单节点规格中 GPU 或 MLU 的卡数;如果是 CPU 规格,则为1。自动生成
/job/hostfile文件。
hostfile 内包含了节点名称和 slots 数目,如对于一个 2机4卡 的任务式训练, hostfile 的内容为:
server1 slots=4 server2 slots=4
slots为单节点规格中 GPU 或 MLU 的卡数;如果是 CPU 规格,则为1。
如用户可以输入以下指令,DeepSpeed 会自动搜索 /job/hostfile 文件完成 2机4卡 的任务式训练。
deepspeed <client_entry.py> <client args> \
--deepspeed --deepspeed_config ds_config.json
更多 DeepSpeed 训练内容,可以查看官方文档:https://deepspeed.readthedocs.io/en/latest/。
单机模式
实际运行指令即为用户输入指令。
断点续训说明
5.0 版本新增: 支持故障时断点保存和继续训练
在训练过程中,由于网卡、板卡等硬件资源出现故障导致训练中断,平台下发异常信号到任务式训练的容器中,触发保存断点时的 checkpoint,并能够重新调度任务式训练,从断点处继续训练。
必须配置专属资源池;
断点保存需要训练框架和算法支持;
只有常规任务式训练支持断点续训;
弹性训练需要算法支持。
预检查说明
断点续训的任务在调度前会先进行环境预检查,预检查的内容包括:环境资源是否充足、板卡状态是否正常及板卡的运行环境等;预检查的结果会写入到任务式训练的事件中。
故障巡检
在断点续训任务运行过程中,平台会对环境进行周期性的硬件检查,包括:网卡、板卡和节点心跳等。当发现异常时,平台会给异常节点上的断点续训任务下发异常信号,触发任务的断点保存, 并重新调度任务式训练。
弹性训练
开启弹性训练的断点续训任务,需要配置 最小节点数;当集群的空闲可用资源在 最小节点数 和 节点数 之间,平台会根据空闲资源量重新设置节点数,调度任务式训练。
弹性训练可能发生在:
任务式训练创建时,集群空闲可用资源不足;
故障触发重新调度后,集群可用的资源不足;
开启了
允许扩缩容时,当任务式训练已经处于缩容状态,且集群有新的空闲资源产生,会触发任务式训练扩容。
性能检测
性能检测功能要求任务的日志中打印每个迭代 e2e时间 和 硬件时间,示例如下:
this iteration hardware time is 2201.521 and e2e time is 3317.794921875 ms.
开启了性能检测的断点续训任务,需要配置 性能阈值;平台会持续检测任务的日志,当 硬件时间 / e2e时间 大于配置的性能阈值时,平台会对任务式训练按照策略,分别处理:
仅告警:邮件通知用户任务式训练性能异常。
重调度并告警:中断任务式训练,重新调度到正常节点中;同时邮件通知用户任务式训练性能异常;
数据准备说明
4.5 版本新增: 支持为训练准备数据
将数据集拷贝至高性能存储(闪存或本地高速存储,由管理员配置)后再执行训练命令,这样可以节省训练时 load 数据的时间,提升训练效率。
数据准备需要一段时间,建议需要长时间训练的任务才开启数据准备功能;开启时,数据集必须只读挂载。
常规任务与批量任务才可以开启数据准备。
数据集在训练完毕后会在节点上保留一段时间(默认 7 天,由管理员配置),超过后会被清理。
如果数据集过大可能会导致节点磁盘使用超出阈值,从而导致节点被巡检组件设为不可调度,这种情况需要联系管理员处理。
调试终端说明
5.0 版本新增: 支持任务式训练开启调试终端
开启终端功能后,任务式训练的每个任务节点会启动一个终端服务。 在运行指令异常结束时,任务式训练会被保存一段时间(默认 4 小时,由管理员配置),在此期间可以通过终端访问容器内部进行调试。
调试服务本身会占用容器少量 CPU、内存资源,并在访问容器内部时会占用部分网络带宽。
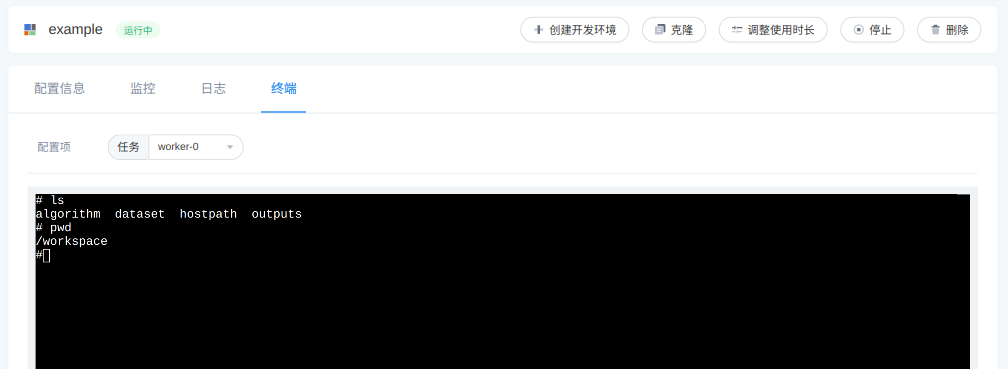
图 235 通过终端访问任务式训练容器内部
调整优先级
可以修改“排队中”的任务式训练的优先级,操作步骤:
左侧功能栏选择“训练管理->任务式训练”;
单击左上角搜索框,选择“状态->排队中”;
选择需要调整优先级的任务,单击该任务的“操作”按钮;
在下拉列表中,单击“调整优先级”;
在弹框中选择目标优先级,普通用户可以选择“正常”和“紧急”两种优先级,管理员可以额外选择“非常紧急”;
单击“确认调整”;
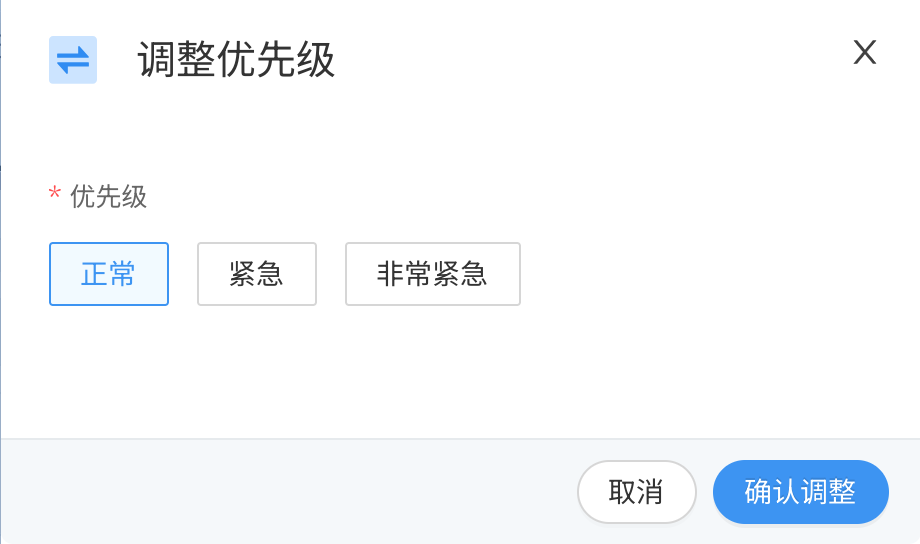
图 236 修改任务式训练优先级
用户在某些项目下处于“运行中”和“排队中”的“紧急”优先级的任务总数是有限的, 达到数量上限后会导致调整到“紧急”优先级失败。
克隆任务式训练
左侧功能栏选择“训练管理->任务式训练”;
选择需要克隆的任务,单击该任务的“操作”按钮;
在下拉列表中,单击“克隆”;
按需调整配置;
单击“创建”。
搜索任务式训练
左侧功能栏选择“训练管理->任务式训练”;
单击左上角搜索框;
在下拉列表中,可基于“名称”、“状态”、“创建人”、“我的算法卷”、“算法收藏”、“算力规格”和“保存模型地址”搜索任务式训练。
批量任务创建 TensorBoard
对于批量任务,可以直接创建 TensorBoard,查看所有子任务的输出结果。
左侧功能栏选择“训练管理->任务式训练”;
单击左上角的“批量任务”;
选择需要可视化的任务,单击该任务的“操作”按钮;
在下拉列表中,单击“创建 TensorBoard”;
按照提示进行配置,参考 表格 177 创建TensorBoard 配置参数 ;
单击“确认”。
状态说明
4.3 版本新增: 任务式训练状态说明
任务式训练的状态有:“排队中”、“运行中”、“错误”、“停止”、“过期”和“成功”。
“过期”:当任务式训练运行时长超过了配置的“使用时长”,会自动变成“过期”状态。
查看任务式训练详情
调整使用时长
4.3 版本新增: 任务式训练支持调整使用时长
用户可以调整“运行中”的任务式训练的使用时长,该操作不会重置容器。
操作步骤:
左侧功能栏选择“训练管理->任务式训练”;
选择需要调整使用时长的任务,单击该任务的“操作”按钮;
在下拉列表中,单击“调整使用时长”;
选择“使用时长” 或输入自定义时长;
单击“确认调整”。

图 237 调整任务式训练使用时长
创建开发环境
4.3 版本新增: 从任务式训练创建开发环境
左侧功能栏选择“训练管理->任务式训练”;
选择需要停止的任务,单击该任务的“操作”按钮;
在下拉列表中,单击“创建开发环境”;
跳转到开发环境创建页,会根据任务式训练的配置信息自动填写好各项配置;
按需修改配置信息;
单击“创建”。
停止任务式训练
左侧功能栏选择“训练管理->任务式训练”;
选择需要停止的任务,单击该任务的“操作”按钮;
在下拉列表中,单击“停止”;
单击“确认停止”。
删除任务式训练
左侧功能栏选择“训练管理->任务式训练”;
单个删除:选择需要删除的任务,单击“操作”按钮,在下拉列表中,单击“删除”;
批量删除:单击表格右上角“编辑”按钮,勾选多个需要删除的任务,单击表格右上角“删除”按钮;
单击“确认删除”。
他人访问权限
4.5 版本新增: 支持为任务式训练配置他人访问权限。
创建时,可以限制同项目内其他用户的访问权限,包括:“可读写”、“只读”和“不可读写”。 应用访问权限不得高于资源访问权限。 若管理员关闭共享权限,则他人访问权限只能为“不可读写”。
不同权限支持的操作如下:
可读写 |
只读 |
不可读写 |
|
|---|---|---|---|
查看详情 |
√ |
√ |
X |
克隆 |
√ |
√ |
X |
创建开发环境 |
√ |
√ |
X |
创建 TensorBoard |
√ |
√ |
X |
调整使用时长 |
√ |
X |
X |
调整优先级 |
√ |
X |
X |
停止 |
√ |
X |
X |
删除 |
√ |
X |
X |