推理任务
模型包创建完成后,可以通过推理任务使用模型包批量推理数据集中的数据。
推理任务为C/S(客户端/服务端)架构。服务端为在线服务;客户端为平台内置的程序, 能够批量处理数据集中的数据,并调用服务端进行推理,最后把结果保存到存储卷中。
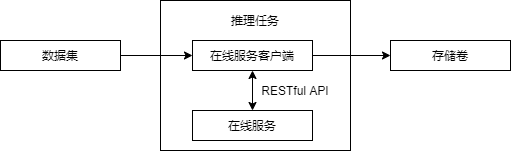
图 270 推理任务原理框图
创建推理任务
直接创建推理任务
左侧功能栏选择“部署上线->推理任务”;
单击右上角的“创建推理任务”;
按照页面提示配置参数:
名称
必填项
说明
推理任务名称
是
数据
是
需要推理的数据集。具体请参见 数据规范 章节
服务类型
是
推理服务端的 API 协议
模型包
是
只能选择对应服务类型的推理模型包
环境变量
否
覆盖模型包中的环境变量值
此选项仅对指定了环境变量的模型包有效
参数
否
覆盖模型包中的参数值
此选项仅对指定了运行参数的自定义服务类型模型包有效
单节点规格
是
推理服务端的单节点算力规格
节点名称
否
指定推理任务可运行的节点,不可与“驱动版本”同时指定
4.2 版本新增: 支持指定可运行节点
驱动版本
否
选择 MLU 或 GPU 规格时可用
节点数
是
推理服务端的节点数
输出
是
推理结果输出存储卷。具体请参见 检测结果 章节
单击“创建”。
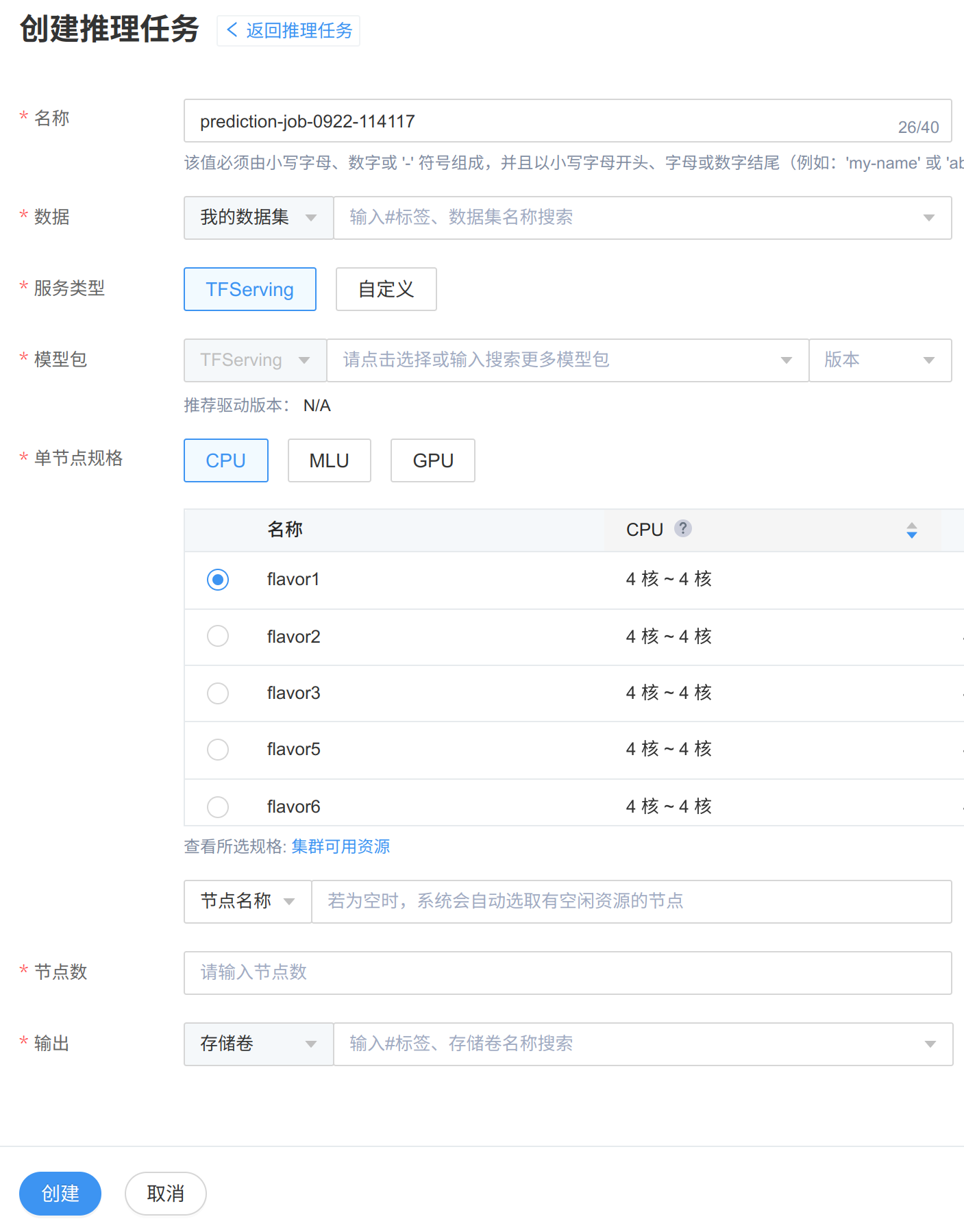
图 271 创建推理任务
节点规格说明
节点规格是推理任务中单个节点的资源配置。
4.0 版本新增: 支持根据所选规格查看集群可用资源
选择一个规格后,单击规格列表下面的 “集群可用资源” 链接;
页面下方会弹出一个表格,展示所选规格对应的可调度节点;
信息包括节点名称,状态,OS 和内核版本,内存, CPU 信息,AI 资源信息,驱动版本,适用算力规格和目前使用情况,以表格形式展示;
表格中内存,CPU 核数,AI 资源数量以分数形式展示,意义为(已经使用的资源 / 资源总量);
状态为空闲时,表示规格申请的资源小于等于节点目前可用的资源;状态为紧张时,表示规格申请的某个或某些资源大于节点目前可用的资源;
目前使用情况的条目显示格式为 1(1):application-name:
1: 物理卡,即板卡在节点中的位置;
(1): 虚拟卡,即板卡切分之后的虚拟卡序号;
application-name: 应用名称。
4.5 版本新增: 直接创建推理任务按照人工智能板卡型号筛选算力规格
选择非 CPU 类型的算力规格;
在算力规格类型下方会出现具体的人工智能板卡型号;
在板卡型号下方统计了当前所有在排队中的应用所需的各型号板卡数量;
选择一个或多个人工智能板卡型号,算力规格列表会根据所选型号过滤。
通过在线服务创建推理任务
查看推理任务详情
搜索推理任务
左侧功能栏选择“部署上线->推理任务”;
单击左上角搜索框;
在下拉列表中,可基于“名称”、“状态”、“创建人”、“算力规格”和“模型包”搜索推理任务。
停止推理任务
左侧功能栏选择“部署上线->推理任务”;
选择需要停止的推理任务,单击该推理任务的“操作”按钮;
在下拉列表中,单击“停止”;
单击“确认停止”。
删除推理任务
左侧功能栏选择“部署上线->推理任务”;
单个删除:查找需要删除的推理任务,单击该推理任务的“操作”按钮,在下拉列表中,单击“删除”;
批量删除:单击表格右上角“编辑”按钮,勾选多个需要删除的推理任务,单击表格右上角“删除”按钮;
单击“确认删除”。
数据规范
待推理数据需要遵循一定的格式规范。具体要求为:
待推理数据必须是一个 JSON 文件。
内容必须是对应在线服务能够接受的格式。比如文件内容为:
{"strData":"data"}
具体格式可参见 访问在线服务 。
一项数据对应一个 JSON 文件。多项数据请放在多个 JSON 文件中。
待推理数据可以放在数据集的任何位置中,推理任务会遍历数据集中的所有 JSON 文件并进行推理。
检测结果
检测结果页面展示了对输入数据集的进行推理后输出的可视化结果。
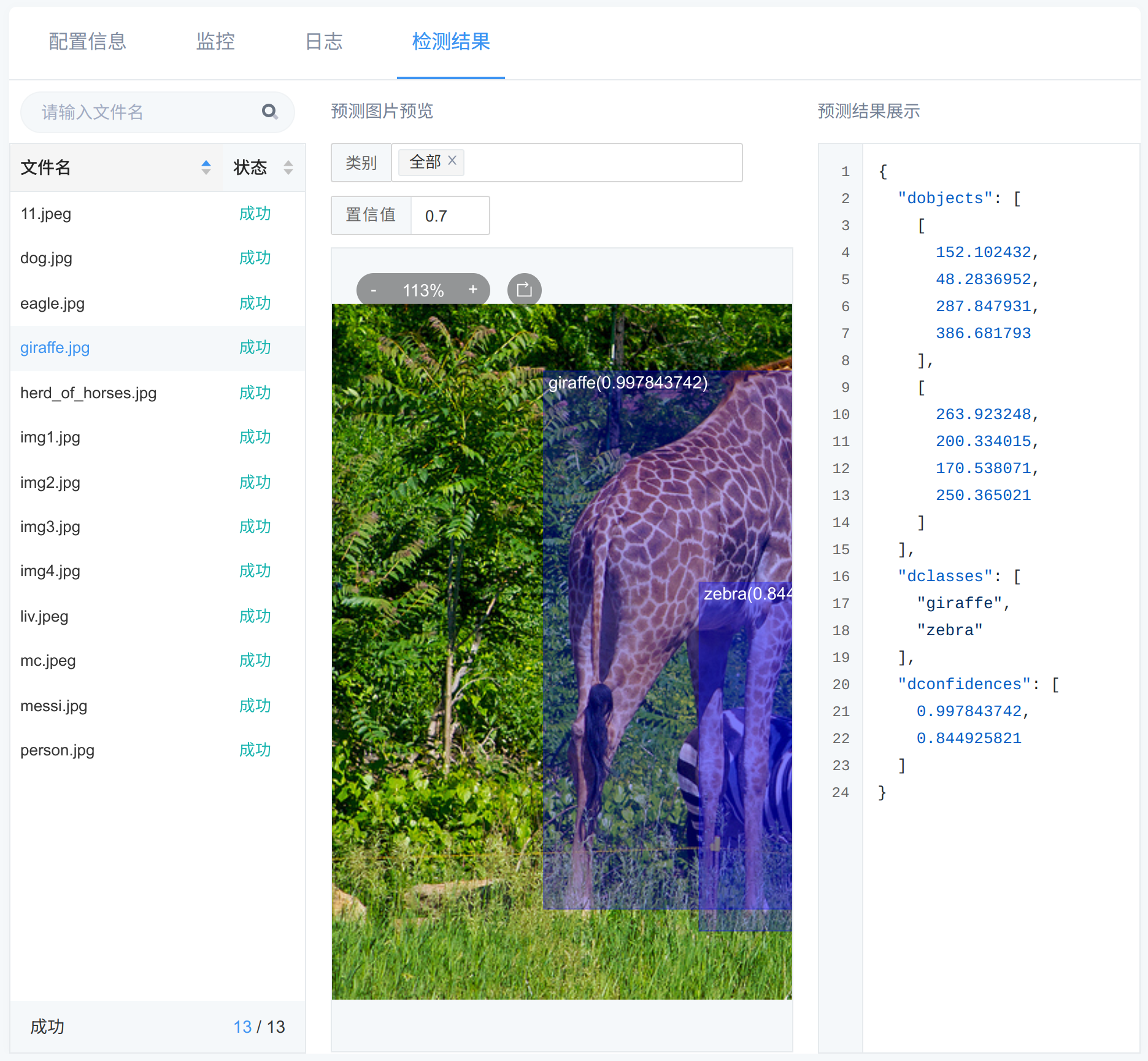
图 273 推理任务的检测结果
检测结果页面左侧为图片列表,点击名称,右侧会展示相应预测图片预览及推理结果。
预测图片预览中包含推理所得标注框,标注框左上角会注明物体的检测类别并在括号中展示其置信度。
推理结果以 JSON 格式展示,包含 dclasses, dobjects, dconfidences, dnum 字段,
分别对应:物体的检测类别列表,物体的检测框坐标列表,每种检测列表的置信度,检测到的物体数。
更多说明可参见 在线测试 中输出格式部分。
检测结果可视化的所需数据源自推理任务输出到存储卷中的文件。若需获取源文件,可查看输出存储卷根目录下和推理任务名同名的目录。
其中存有 result 文件夹和 result.ndjson 文件。
result 文件夹存放所有图片的推理结果。result.ndjson 文件存放图片路径和图片检测结果,示例如下:
{"source":"/workspace/dataset/private/fig1.jpeg","status":"SUCCEEDED","resultLocation":"result/private/fig1.jpeg_result.json"}
{"source":"/workspace/dataset/private/fig2.jpeg","status":"FAILED","errorMesssage":"unexpected protocol"}
每行 JSON 对应一张图片的检测结果,包含 source, status, resultLocation, errorMesssage 字段,
分别表示: 图片存放路径,图片检测状态,检测结果存放路径,推理错误原因。