评估任务
支持运行评估模型的任务,输出对模型的评估结果,以及模型对图片的检测结果,支持查看任务运行时的日志和资源使用率。 模型的评估结果,以及模型对图片的检测结果,均可在前端进行可视化展示。
评估结果以文件形式存储,要求文件名为 evaluation.json ,格式符合 可视化文件格式 。具体可参考 可视化文件 。
模型对图片的检测结果以若干固定格式的文件及目录存储,文件结构和格式要求可参考 检测结果。
创建评估任务
左侧功能栏选择“验证评估->评估任务”;
单击右上角“创建评估任务”;
按照页面提示配置参数:
表 192 创建评估任务参数 名称
必填项
说明
评估任务名
是
他人访问权限
是
具体参见 他人访问权限
任务类型
是
支持“图像”、“视频”、“音频”、“表格”、“自定义”
应用场景
是
任务类型为非“自定义”时,
可选应用场景。参考 应用场景说明
模型来源
是
仅任务类型为非“自定义”时需选择,
支持 “预置模型训练”、“模型”
数据
任务类型为
“自定义”
是
可选 “我的数据集”、“标注数据集”
或 “数据集收藏”
任务类型为
非“自定义”
是
可选任务类型对应的 “标注数据集”
算法
是
可选 “算法卷” 或 “Git 仓库”,参考 算法说明
模型
模型
是
从 “我的模型” 中选择模型卷,参考 模型说明
文件夹
是
模型卷中模型所在路径
对于所选模型卷,平台仅挂载该路径中内容
参考 模型说明
运行指令
是
运行评估算法,输出 可视化文件,
预置模型训练
是
已经运行成功的预置模型训练任务,
使用其模型完成评估
镜像
是
镜像适用范围需包含“评估任务”
镜像适用板卡类型需和单节点规格一致
单节点规格
是
评估任务的算力规格
节点名称
否
指定评估任务可运行的节点,不可与“驱动版本”同时指定
4.2 版本新增: 支持指定可运行节点
驱动版本
否
选择 MLU 或 GPU 规格时可用
更多设置
存储卷
否
单击“创建”。
应用场景说明
不同任务类型支持的应用场景如下:
图像:图像分类单标签、物体检测矩形框、实例分割、语义分割、OCR 标注、关键点标注。
视频:视频分类单标签、视频检测、目标追踪。
音频:音频分类单标签、音频转写。
表格:表格预测、时序预测。
算法说明
不同任务类型、不同模型来源下的算法含义有所区别:
模型说明
“模型”在以下两种情况下被选择:
任务类型为“自定义”。
任务类型为非“自定义”,但模型来源为“模型”。
当任务类型为非“自定义”,且模型来源为“预置模型训练”,不再显式选择“模型”,任务将评估所选“预置模型训练”生成的模型。
运行指令说明
不同任务类型、不同模型来源下的运行指令含义有所区别:
节点规格说明
节点规格是评估任务中单个节点的资源配置。
4.0 版本新增: 支持根据所选规格查看集群可用资源
选择一个规格后,单击规格列表下面的 “集群可用资源” 链接;
页面下方会弹出一个表格,展示所选规格对应的可调度节点;
信息包括节点名称,状态,OS 和内核版本,内存, CPU 信息,AI 资源信息,驱动版本,适用算力规格和目前使用情况,以表格形式展示;
表格中内存,CPU 核数,AI 资源数量以分数形式展示,意义为(已经使用的资源 / 资源总量);
状态为空闲时,表示规格申请的资源小于等于节点目前可用的资源;状态为紧张时,表示规格申请的某个或某些资源大于节点目前可用的资源;
目前使用情况的条目显示格式为 1(1):application-name
1: 物理卡,即板卡在节点中的位置;
(1): 虚拟卡,即板卡切分之后的虚拟卡序号;
application-name: 应用名称。
4.5 版本新增: 创建评估任务按照人工智能板卡型号筛选算力规格
选择非 CPU 类型的算力规格;
在算力规格类型下方会出现具体的人工智能板卡型号;
在板卡型号下方统计了当前所有在排队中的应用所需的各型号板卡数量;
选择一个或多个人工智能板卡型号,算力规格列表会根据所选型号过滤。
评估任务目录结构
评估任务容器内的目录结构为:
/
└── workspace
├── algorithm(创建时选择的算法卷)
├── dataset
│ ├── private
│ │ ├── 我的数据集名字 A
│ │ └── 我的数据集名字 B
│ └── favorite
| ├── 收藏数据集名字_A
| │ └── 收藏数据集版本名字_A
| └── 收藏数据集名字_B
| └── 收藏数据集版本名字_B
├── model
│ └── private
│ └── 我的模型卷名字 (映射到 创建时选择的模型文件夹)
│ └── evaluation (映射到 创建时选择的模型文件夹/evaluation/评估任务名)
└── volume
├── 存储卷名字 A
└── 存储卷名字 B
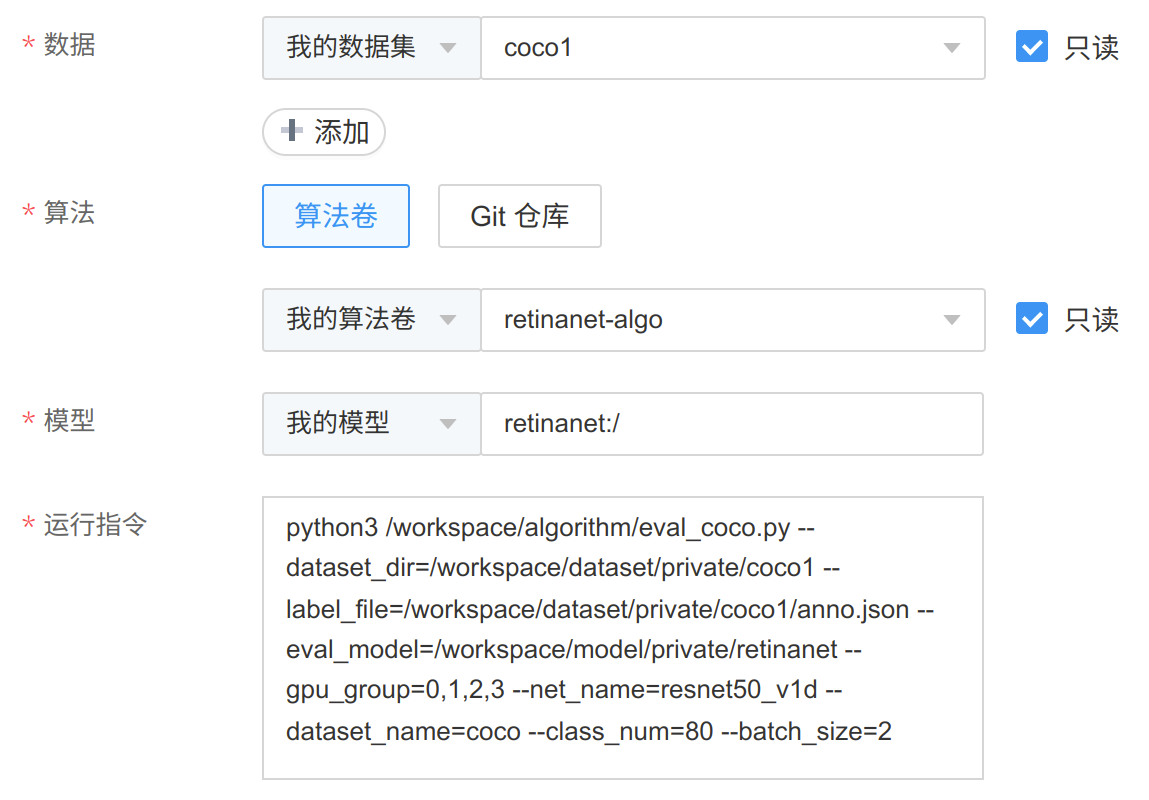
图 240 评估任务运行指令
以上图为例,模型评估的代码,需要将结果保存到 /workspace/model/private/model1/evaluation/evaluation.json 文件,
运行时,需要从 /workspace/model/private/model1/ 加载模型。
另外,模型评估的代码,需要将检测结果保存到 /workspace/model/private/model1/evaluation/detection 路径中,
包含的文件内容和格式要求可参考 检测结果。
以上路径均为运行评估任务的容器内路径,若在平台上查看输入输出文件,模型文件来自 model1 的 subpath1/subpath2 目录。
评估结果保存在 model1 的 subpath1/subpath2/evaluation/jobname/evaluation.json 。检测结果保存在 model1 的
subpath1/subpath2/evaluation/jobname/detection 目录。
可视化文件
平台只能读取符合规定格式的评估结果,并绘制图表。
可视化文件名字需为 evaluation.json ,格式参见 可视化文件格式 。
可以包含一个或多个图表的分类,每个分类可包含一张或多张图表。
可视化文件例子
list 图表
list 图表为键值对。平台只读取 JSON 文件中
series字段中第一项,按data字段顺序展示所有元素,每行显示三个。evaluation.json文件内容:[ { "category": "分类1", "charts": [ { "type": "list", "title": "list 图表 A", "series": [ { "data": [ ["键1", "值1"], ["键2", "值2"], ["键3", "值3"], ["键4", "值4"], ["键5", "值5"] ] } ] } ] } ]
展示效果:

图 241 评估任务 list 图表展示效果
bar 图表
bar 图表为柱状图。平台只读取 JSON 文件中
series字段中第一项,data字段每个元素第一项为 x 轴取值,第二项为 y 轴取值。evaluation.json文件内容:[ { "category": "分类2", "charts": [ { "type": "bar", "title": "bar 图表 A", "series": [ { "data": [ ["分类1", 1], ["分类2", 3], ["分类3", 5] ] } ] } ] } ]
展示效果:

图 242 评估任务 bar 图表展示效果
table 图表
table 图表为表格。JSON 文件中
series字段数组每个元素指定表格的一行,name字段指定行名,data字段每个元素指定某一行的每一列。第一项为列名,第二项为取值。evaluation.json文件内容:[ { "category": "分类3", "charts": [ { "type": "table", "title": "table 图表 A", "series": [ { "name": "行1", "data": [ ["列1", 1], ["列2", 3], ["列3", 5] ] }, { "name": "行2", "data": [ ["列1", 2], ["列2", 4], ["列3", 6] ] } ] } ] } ]
展示效果:

图 243 评估任务 table 图表展示效果
line 图表
line 图表为折线图。
无下拉框的 line 图表
x_axis字段和y_axis字段分别指定 x 轴和 y 轴的名称(name字段)和类型(type字段,可为数值value或类型category)。type字段为value时,data字段的值需要为数值,同时可以指定数值间隔(interval字段)。series字段的每个元素代表一条线,name字段可以指定曲线名字。data字段每个元素是(x,y)坐标。evaluation.json文件内容:[ { "category": "分类4", "charts": [ { "type": "line", "title": "无下拉框曲线图表", "x_axis": { "interval": 0.1, "type": "value", "name": "召回率" }, "y_axis": { "interval": 0.1, "type": "value", "name": "精确率" }, "series": [ { "name": "曲线1", "data": [ [0.0, 1.0], [0.1, 1.0], [0.2, 1.0], [0.3, 0.5], [0.4, 0.5], [0.5, 0.3], [0.6, 0.3], [0.7, 0.1], [0.8, 0.1], [0.9, 0.1], [1.0, 0.1] ] }, { "name": "曲线2", "data": [ [0.0, 1.0], [0.1, 1.0], [0.2, 1.0], [0.3, 0.5], [0.4, 0.5], [0.5, 0.5], [0.6, 0.5], [0.7, 0.1], [0.8, 0.1], [0.9, 0.1], [1.0, 0.1] ] } ] } ] } ]
展示效果:

图 244 评估任务 line 图表展现效果(无下拉框)
line 图表增加下拉框
首先在
charts下的drop_down字段中定义每个下拉框。 可以指定下拉框的名字(name字段)、取值范围(items字段)、是单选框还是多选框(type字段,single或multiple)。然后在
series的每个元素中增加drop_down字段,包含定义好的下拉框的一种取值组合。line 图表使用多 JSON 拆分数据
在数据量比较大时,可以拆分 JSON 文件。需要将
data字段换成file字段,以指定拆分的 JSON 文件。文件路径需要相对evaluation.json文件所在目录。
下拉框和拆分 JSON 的例子:
evaluation.json文件内容:[ { "category": "分类4", "charts": [ { "type": "line", "title": "有下拉框曲线图表", "drop_down": [ { "items": [0.5, 0.55], "type": "single", "name": "iou 阈值" }, { "items": ["rongyuan"], "type": "single", "name": "分类" } ], "x_axis": { "interval": 0.1, "type": "value", "name": "召回率" }, "y_axis": { "interval": 0.1, "type": "value", "name": "精确率" }, "series": [ { "drop_down": { "分类": "rongyuan", "iou 阈值": 0.5 }, "file": "line_iou_0.5.json" }, { "drop_down": { "分类": "rongyuan", "iou 阈值": 0.55 }, "data": [ [0.0, 1.0], [0.1, 1.0], [0.2, 1.0], [0.3, 0.5], [0.4, 0.5], [0.5, 0.5], [0.6, 0.5], [0.7, 0.1], [0.8, 0.1], [0.9, 0.1], [1.0, 0.1] ] } ] } ] } ]
拆分出来的 JSON 文件(
line_iou_0.5.json)样例如下:[ [0.0, 1.0], [0.1, 1.0], [0.2, 1.0], [0.3, 1.0], [0.4, 0.5], [0.5, 0.3], [0.6, 0.3], [0.7, 0.2], [0.8, 0.2], [0.9, 0.2], [1.0, 0.1] ]
展示效果:

图 245 评估任务 line 图表展现效果(有下拉框)
progress 图表
progress 图表为百分比图。
series字段和drop_down字段同 line 图表。data字段里每个元素是一组键值对,键是图里百分比代表的类型,值是该类型所占百分比值。evaluation.json文件内容:[ { "category": "分类5", "charts": [ { "drop_down": [ { "items": [0.5, 0.55], "name": "iou 阈值", "type": "single" } ], "title": "漏检分析", "type": "progress", "series": [ { "drop_down": { "iou 阈值": 0.5 }, "data": [ ["laptop", 34.88], ["handbag", 17.44], ["knife", 17.44], ["bench", 11.63], ["skis", 11.63], ["bottle", 6.98], ["backpack", 0.0], ["umbrella", 0.0] ] }, { "drop_down": { "iou 阈值": 0.55 }, "data": [ ["laptop", 32.61], ["handbag", 16.3], ["knife", 16.3], ["bench", 10.87], ["skis", 10.87], ["bottle", 13.04], ["backpack", 0.0], ["umbrella", 0.0] ] } ] } ] } ]
展示效果:

图 246 评估任务 progress 图表展示效果
heatmap 图表
heatmap 图表为热力图。
x_axis字段和y_axis字段中类型type需要指定为category。data是坐标轴上各类别的名称数组。series字段中data是由三元数组构成的数组,三元数组前两个元素分别指定了 x 轴和 y 轴位置,第三个元素指定了该位置的取值。 也可以通过file字段指定 JSON 数据文件,文件格式与data字段格式相同。evaluation.json文件内容:[ { "category": "分类6", "charts": [ { "title": "混淆矩阵-1", "type": "heatmap", "x_axis": { "name": "Predicated Label", "type": "category", "data": ["分类1", "分类2", "分类3", "分类4", "分类5"] }, "y_axis": { "name": "True Label", "type": "category", "data": ["分类1", "分类2", "分类3", "分类4", "分类5"] }, "series": [ { "data": [ [0, 0, 1],[0, 1, 0],[0, 2, 0],[0, 3, 0],[0, 4, 0], [1, 0, 0],[1, 1, 1],[1, 2, 0],[1, 3, 0],[1, 4, 0], [2, 0, 0],[2, 1, 0],[2, 2, 1],[2, 3, 0],[2, 4, 0], [3, 0, 0],[3, 1, 0],[3, 2, 0],[3, 3, 1],[3, 4, 0], [4, 0, 0],[4, 1, 0],[4, 2, 0],[4, 3, 0],[4, 4, 1] ] } ] } ] } ]
展示效果:

图 247 评估任务 heatmap 图表展示效果
检测结果
检测结果页面展示了被评估模型对输入数据集进行推理后输出的可视化结果。
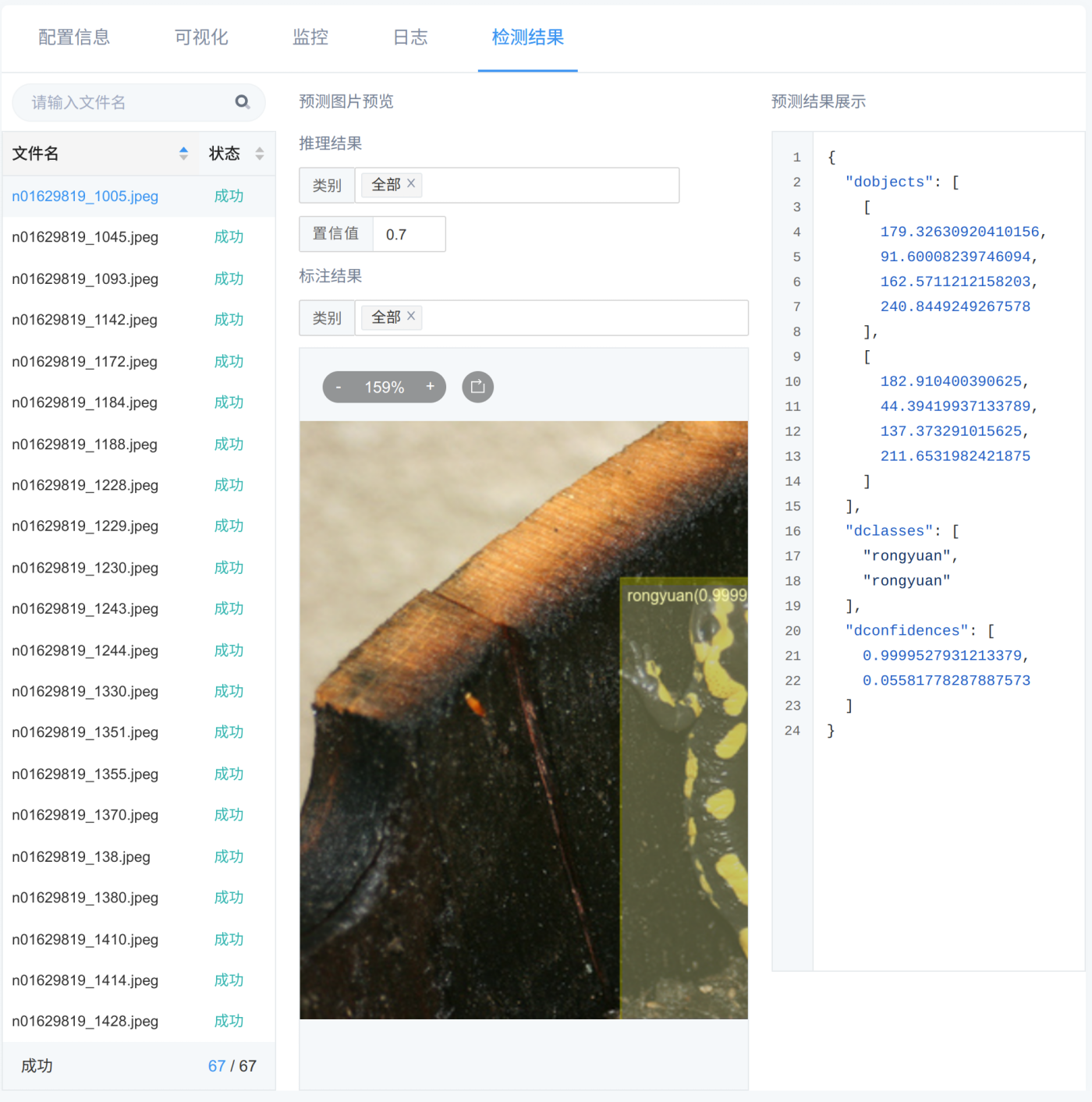
图 248 评估任务中模型对数据集的检测结果
上图左侧为图片列表,点击名称,右侧会展示相应预测图片预览及推理结果。预测图片预览中包含推理所得标注框及真实标注框。 推理所得标注框用蓝色标识,标注框左上角会注明物体的检测类别并在括号中展示其置信度,真实标注框用黄色标识,在标注框右下角展示物体类别。
平台通过读取符合规定格式的文件来获取上图所示的可视化展示。因此评估代码需将推理结果输出到若干固定格式的文件及目录中。
其中,所有的推理结果需要保存在容器模型卷目录下 evaluation/detection 路径中,例如 评估任务目录结构 给出的示例中,
该路径为 /workspace/model/private/model1/evaluation/detection。 detection 目录下需要包括 result.ndjson 文件,
检测结果文件,ground_truth 目录。完整输出文件目录示例如下:
/
└── evaluation
└── detection
├── result.ndjson
├── result1.json (检测结果文件)
├── result2.json (检测结果文件)
├── ...
└── ground_truth
├── result.ndjson
├── result1.json (标注信息文件)
├── result2.json (标注信息文件)
└── ...
文件的含义及格式如下:
result.ndjson
该文件记录图片路径和检测结果。 每行 JSON 对应一张图片的检测结果,包含
source,status,resultLocation字段, 分别表示图片存放路径,图片检测状态,检测结果存放路径。示例如下:{ "source": "/workspace/dataset/private/coco/1.JPEG", "status": "SUCCEEDED", "resultLocation": "result1.json"} { "source": "/workspace/dataset/private/coco/2.JPEG", "status": "SUCCEEDED", "resultLocation": "result2.json"} ...
检测结果文件
该文件记录每张图片的检测结果,一张图片对应一个单独的文件,文件名不能重复,并且和
result.ndjson中resultLocation字段值一一对应。文件为 JSON 格式,包含dclasses,dobjects,dconfidences字段,分表对应:物体的检测类别列表, 物体的检测框坐标列表,每种检测列表的置信度。示例如下:{ "jsonData": { "dclasses": ["rongyuan"], "dobjects": [[39.09, 113.08, 369.53, 145.94]], "dconfidences": [0.99] } }
更多说明可参见 在线测试 中输出格式部分。
ground_truth
该目录包含图像的真实标注信息,用于和推理得到的标注结果进行对比。目录内需包含
result.ndjson文件和标注信息文件。result.ndjson文件记录图片路径及包含图片标注信息的文件路径,格式和推理结果的result.ndjson文件基本一致,但不需要 “status” 字段,示例如下:{ "source": "/workspace/dataset/private/coco/1.JPEG", "resultLocation": "result1.json"} { "source": "/workspace/dataset/private/coco/2.JPEG", "resultLocation": "result2.json"} ...
标注信息文件保存图片的真实分类及其标注框坐标,格式和推理结果的检测结果文件基本一致,但是不需要
dconfidences字段 。示例如下:{ "jsonData": { "dclasses": ["rongyuan"], "dobjects": [[39, 114, 370, 146]], } }
克隆评估任务
左侧功能栏选择“验证评估->评估任务”;
选择需要克隆的评估任务,单击该任务的“操作”按钮;
在下拉列表中,单击“克隆”;
按需调整配置;
单击“创建”。
搜索评估任务
左侧功能栏选择“验证评估->评估任务”;
单击左上角搜索框;
在下拉列表中,可基于“名称”、“状态”、“创建人”、“我的算法卷”、“算法收藏”、“数据集收藏”、“我的数据集”、“算力规格”和“保存模型地址”搜索评估任务。
查看评估任务详情
停止评估任务
左侧功能栏选择“验证评估->评估任务”;
选择需要停止的评估任务,单击该任务的“操作”按钮;
在下拉列表中,单击“停止”;
单击“确认停止”。
删除评估任务
左侧功能栏选择“验证评估->评估任务”;
单个删除:查找需要删除的评估任务,单击该任务的“操作”按钮,在下拉列表中,单击“删除”;
批量删除:单击表格右上角“编辑”按钮,勾选多个需要删除的评估任务,单击表格右上角“删除”按钮;
单击“确认删除”。
他人访问权限
4.5 版本新增: 支持为评估任务配置他人访问权限。
创建时,可以限制同项目内其他用户的访问权限,包括:“可读写”、“只读”和“不可读写”。 应用访问权限不得高于资源访问权限。 若管理员关闭共享权限,则他人访问权限只能为“不可读写”。
不同权限支持的操作如下:
可读写 |
只读 |
不可读写 |
|
|---|---|---|---|
查看详情 |
√ |
√ |
X |
克隆 |
√ |
√ |
X |
停止 |
√ |
X |
X |
删除 |
√ |
X |
X |